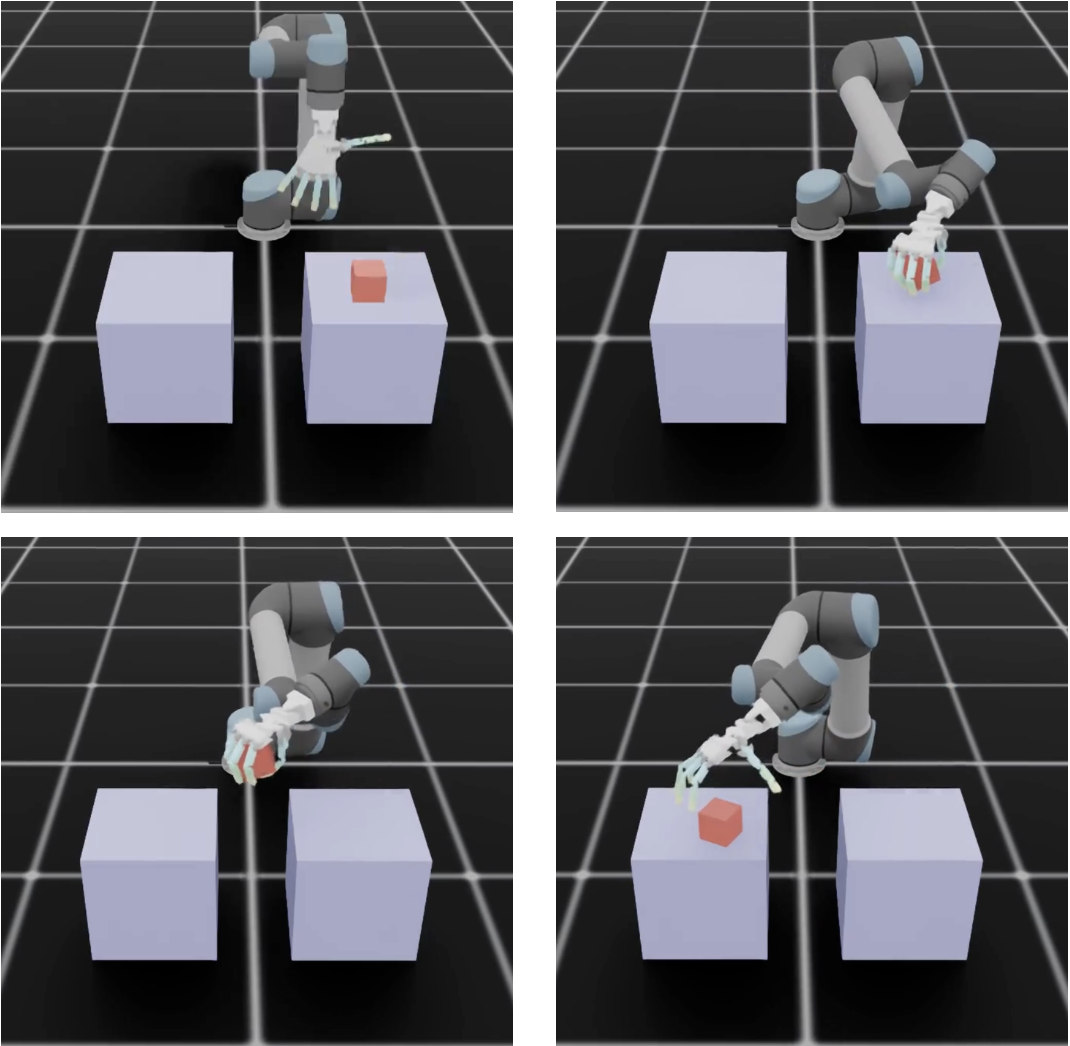
Imitation Learning & IRL for Dexterous Manipulation (MSc Thesis, 2025)
Student: Gregorio Valenti
Supervision: Andreas Schlaginhaufen, Cheng Peng (CREATE Lab, EPFL)
Goal: Build an imitation-learning pipeline for controlling a custom dexterous robotic hand, using demonstrations collected via a VR teleoperation setup.
Work:
Developed a VR teleoperation + data collection pipeline for the ADAPT hand in NVIDIA Isaac Sim to gather expert demonstrations.
Implemented and benchmarked behavioral cloning (BC), inverse RL (IRL), and RL fine-tuning on simulated pick-and-place tasks.
Outcome:
Achieved successful pick-and-place in simulation with a 22-DoF dexterous hand setup.
Demonstrated that BC benefits from RL/IRL refinement, indicating a promising hybrid approach for dexterous manipulation.
Imitation Learning for Autonomous Car Racing (MSc Project, 2024)
Student: Emre Gursoy
Supervision: Andreas Schlaginhaufen, Johannes Waibel (PREDICT Lab, EPFL)
Goal: Learn stable control policies for an autonomous race car from expert demonstrations.
Work:
Augmented expert demonstrations with stabilizing inputs (using replica noising) to improve closed-loop stability of the behavioral cloning policy.
Evaluated against vanilla BC in both simulation and real-world racetrack experiments.
Outcome:
Achieved a stable BC policy in simulation and on track, improving behavior from immediate crashes to successful lap/track completion.
Constrained RL & IRL on JetBot Testbed (MSc Theses, 2023)
Students: Alexandre Clivaz, Pierre Chassagne
Supervision: Andreas Schlaginhaufen, Tony Wood
Goal: Develop and deploy constrained RL and IRL methods on a wheeled mobile-robot testbed to navigate a maze and reach the nearest exit safely.
Work:
Performed system identification and built a simulation model of the JetBot platform.
Collected real-world expert demonstrations and trained a behavioral cloning (BC) baseline.
Implemented constrained RL and IRL in simulation, ensuring safety during navigation.
Trained a perception module for real-world obstacle detection.
Executed sim-to-real transfer and improved performance and safety via online RL fine-tuning on the robot.
Outcome:
Learned safe navigation policies in simulation using constrained RL and IRL.
Successfully deployed policies on the real robot, improving safety and performance through online RL fine-tuning.